In the era of Big Data, these pipelines must provide not only accessibility and efficiency to data, but also high-throughput and scalability while maintaining low-latency. This article has gathered insights on how streamlining your Big Data architecture can help you meet these network requirements.
Why it is important:
Data pipelines are used to combine, process, and consolidate data into one system. While doing so, they need to achieve high throughput and low latency. Without these two metrics, valuable time and dollars are wasted.
What’s ahead:
This article will help you understand Big Data Pipelines by taking you through the following topics:
- Stages of Big Data Pipeline
- Need for high-throughput and low-latency
- Big Data Architectural Choices
- Components of Big Data Architecture
Big Data Pipeline
Big Data pipelines create a seamless flow of operations from the collection of data to its insightful application. Typical stages of the Big Data pipeline are:
- Collection
- Ingestion
- Preparation
- Computation
- Presentation
Most efforts are gone in the collection, ingestion, and preparation stages—collectively known as data engineering.
The pipeline is triggered with data collection that involves the extraction of data from multiple sources, including websites, apps, devices, microservices, and analytics. Once the data is received, it is dropped into a data lake. The data is then cleaned—mostly using the extract, transform, load (ETL) approach—and catalogs in a ready-to-use format for data warehouse storage.
At data warehouses, several algorithms, including analytics, machine learning, or other data science procedures, are used for computation to deliver models and insights. Lastly, the insights obtained are delivered to the final users through dashboards, notifications, microservices, and other interfaces.
High-Throughput and Low-Latency
Big Data pipelines are measured by two primary metrics:
High-throughput: How much data can be transmitted from one place to another in a given time
Low-latency: Minimal to zero delays to produce outcome from the input
Meeting the requirement of high-throughput and low-latency is not easy. Pursuing these two metrics can bring up several challenges, creating trade-offs in other network characteristics affecting performance.
Several measures are taken to improve throughput, such as using Optimal Superframe and Data Buffer Scheme (OSDBS), parallelized decision-making, and RDMA. However, meeting high-throughput requirements also creates a few challenges:
- Without the ability to scale to meet the size of workloads, high-throughput cannot be achieved
- The cost of processing large packets to achieve high-throughput can undermine the value of investments if your tech stack is not designed to deal with high data rates
- Large packets can increase memory requirements, slowing down brokers that handle client requests. Thus, it can be expensive if it must be done without compromising much on other network characteristics
Several methods are used to achieve low-latency. The most promising way is to divide your processing work between ingest and query time such that most work is managed during ingest, thus lowering latency. However, this can also make ingestion expensive. Moreover, reducing latency can affect other network characteristics like accuracy, which shouldn’t be compromised. Also, for your data to reach the destination faster, more bandwidth is consumed, which is another challenge.
Can we achieve high-throughput and low-latency without compromising other network characteristics? The answer is yes.
Monitoring endpoints that cause the most latency can help you understand and mitigate bottlenecks. However, this is only a half-baked measure. To bring a real transformation in your network performance, you need to create flexibility in your Big Data architecture, so your pipelines are aligned to meet the needs of high-throughput and low-latency.
Architectural Choices for Big Data Pipeline
Data lakes, warehouses, and the pipeline must be structured to make way for high-throughput and low-latency. A way to do this is by creating a balance between batch and stream processing during computation. This can be easily done in lambda architecture divided into three layers:
- Batch layer – takes care of throughput with comprehensive and economic mapping
- Speed layer – takes care of real-time streaming
- Serving layer – combines the outputs from both and provides complete results
AWS has built a Well-Architected Review (WAR) framework to guide you on architectural best practices for high-performance data pipelines. It helped InterMiles, a travel and lifestyle reward program, align its architecture with the cloud best practices.
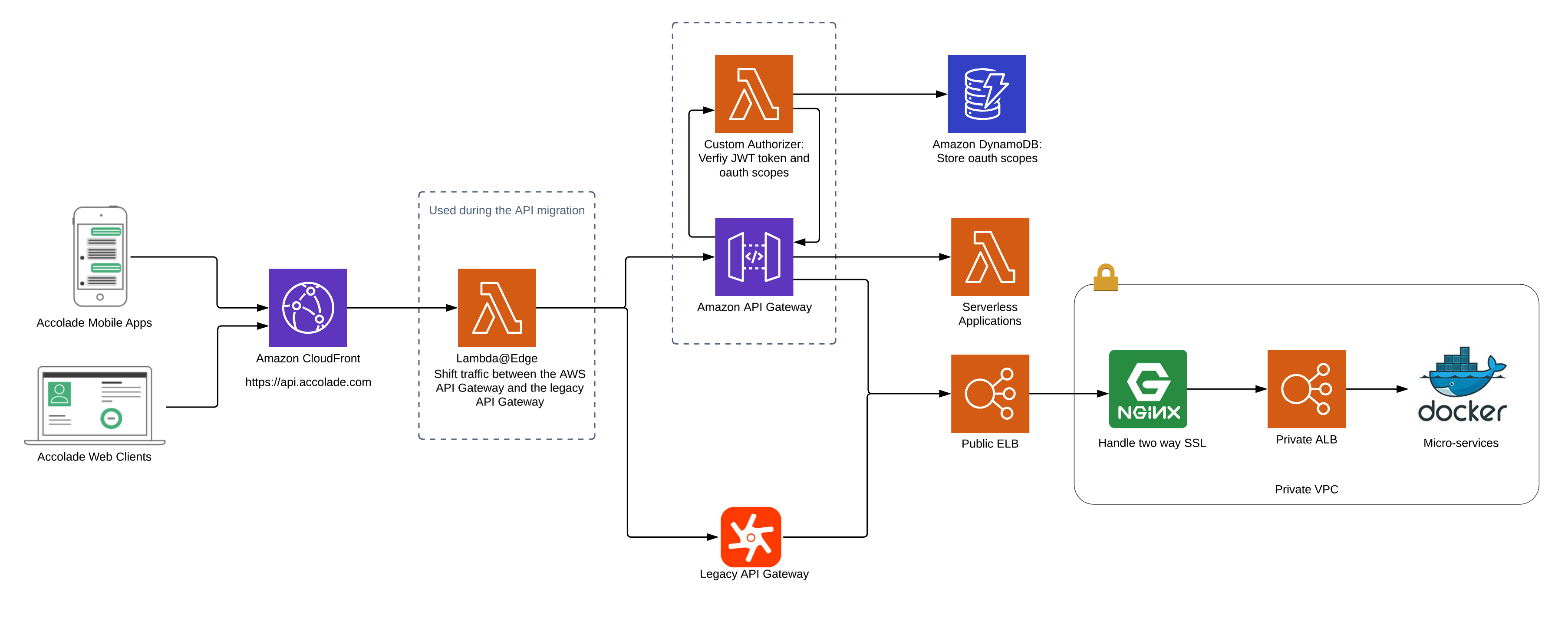
Source: AWS Lambda
While building an architecture for big data, its components play a significant role in determining the level of performance your system will deliver. These components include Endpoints, Message Queue, Data Store, Infrastructure, Computer Engine, and ML Framework. While your endpoints, message queue, and storage capacity together influence the throughput of your network, computation and databases can influence its latency. Thus, the best way to achieve the desired levels of throughput and latency is to understand the role these components play and make the right choices in the selection of your tech stack to ensure the best performance.
| Architectural components |
Technology choices |
| Endpoints |
REST/MQTT end points are the most suitable protocols for Big Data applications |
| Message Queue |
Kafka provides a high ingestion rate |
| Data Store |
Hadoop HDFS data lakes and AWS S3 cloud storage provide high-volume storage at a low cost. |
| Query Infrastructure |
Apache Hive is a popular language to convert data lakes into data warehouses. |
| Computes |
Hadoop Map-Reduce and Apache Spark provide batch computer engines to deliver high-throughput, while Apache Storm, Flink, and Beam on a stream runner can help with latency needs. |
AWS, Microsoft Azure, and Google Cloud Platform (GCP) also offer serverless computing choices for Big Data architecture. In a serverless architecture, the codes run on containers, and for any storage requirements, communication is established with the backend.
Serverless analytics flow through four layers of the pipeline:
- Data collection – continuously pulls data from multiple sources and creates a real-time data stream to push to the next layer of processing
- Data streaming – continuous flow of data and thus, uses real-time storage units that are scaled up and down based on the flow of data
- Data processing – data goes through a series of processes including preparation, cleaning, validation, and transformation
- Data serving – receives processed data. This can work in real-time and as a new record enters a database, it is quickly processed and written into another stream. For this, AWS provides a Lambda function for DynamoDB streams. Google offers PUB/SUB functions with Data Proc. Azure EventHub and serverless functions are provided by Microsoft for the same purpose
There are several benefits of serverless architecture:
- Developers do not have to worry about the infrastructure when codes run in containers
- Resources can be scaled up or down as per the requirement. An example is AutoScale in the Kubernetes cluster
- The payment is made only for the execution of the code, and thus, the infrastructure cost is reduced. It is most suitable for less-used endpoints
- The availability of your application is high with nearly no downtime as clusters are immediately redeployed in case of any cluster failures.
Pursuing High-Throughput, Low-Latency Big Data Pipelines
High-throughput and low-latency pipelines create high customer satisfaction that brings high revenues. Organizations need to realize that these are not merely selective requirements but mandates considering the speed at which the digital world is growing today. You must design your architecture with these considerations of network performance if you want to keep up with your competition.
To help us assist you in designing an architecture that fits the needs of your organization and customers, check out Apexon’s Data Engineering Services or get in touch directly using the form below.



