Data pipelines are designed based on data volumes, their purpose of movement, and dynamics of usage. Data pipeline design patterns create the foundation for the development of a data solution and thus, are widely used in software engineering. This article discusses various design patterns of data pipelines to help data engineers and architects select the most appropriate pattern to meet their data needs.
What’s ahead:
This article will help you understand more about data pipelines by covering the following topics:
- What is a data pipeline?
- Data Pipeline Vs Extract, Load, Transform
- Data pipeline design patterns
- DAG (Directed Acyclic Graph)
- Lambda architecture
What is a Data Pipeline?
Organizations generate large volumes of data multiplied by a variety of sources. However, this data can deliver a business value only when it is efficiently aggregated to create a single moment of truth. This requires transfer of data from scattered sources to unified destinations. Data pipelines help in transferring data from multiple sources to destinations using a series of digital processes.
A data pipeline has some major components:
- Source
- Destination
- Processing
- Workflow
- Monitoring
Sources: Sources are usually databases or applications that produce raw data. Geographical distances between different cities of the world generated by Google Earth can be an example. Similar data can also be obtained from other sources like Esri open data hub, USGS Earth Explorer, and NASA’s SEDAC (Socioeconomic Data and Applications Center). A data pipeline allows extraction of data from such multiple sources. Within your organization, your team may be fetching marketing data from multiple platforms like Hubspot, Marketo, Pardot, or Eloqua sales data or use applications like Salesforce or Oracle.
Destination: Destination is either an on-premises application or a cloud repository such as a data store, data warehouse, data lake, data mart. A data lake would simply store the aggregated data while data warehouse would allow further processing. Data marts are subsets of data warehouses that are used for storing and processing data that belongs to specific territories or departments and this data is often used for real time analytics. Data lake is another form of repository that allows storage of data as it is in structured, semi-structured and unstructured formats.
Processing: Between the sources and destination sits a processing unit of the data pipeline. The raw data is first ingested into this pipeline using a push mechanism. This can be done periodically in batches or continuously through stream processing. In batch processing, data is processed hourly or daily and is often scheduled during the times of minimum load on a system. However, with batch processing, any failure occurring at that start of a batch can cause errors later. Stream processing, on the other hand, takes data in real-time. Of course, this adds challenges like duplication and idempotency. It is also more challenging to get started with stream processing compared to batch processing. However, stream processing is superior when it comes to speed and scalability.
While processing the data, it is often transformed using processes like standardization sorting, deduplication, validation, and verification so that it can be converted into usable information at the other end to support business insights. Data pipelines can also automate data transformation and optimization in an interim storage space before the data can be moved to the destination. For transforming data, compute services are used such as Amazon EC2 for Linux and Amazon EMR with Apache Hadoop and Spark frameworks.
Workflow: The speed and effectiveness of the data flow within a pipeline depend on the sequence it follows which is affected by technical and business dependencies. Technical dependency could be needed for data validation while business dependency could result from the need for cross-verification of the data with multiple sources to ensure data accuracy.
Monitoring: The monitoring component allows spotting and fixing of failures to ensure data integrity and make way for smooth operations. Users are alerted about failure scenarios like congestion, offline destination, lack of support for connection, browser cache issues, differences in schemas, capacity limits, and so on. Activities in the pipeline are usually monitored visually. Azure Data Factory V2 allows visual monitoring of data pipelines and showcase list of activity runs, ordering, filtering, and reorders.
How is a Data Pipeline Different from an ETL (Extract, Transform, Load) Pipeline?
Data pipeline describes processes that are used for moving data from one system to another. It is a broad term that covers all forms of data movements such as batch processing and real-time processing from cloud-native sources or low-cost open-sources. However, it does not necessarily involve data transformation or loading.
Alternatively, ETL covers processes that involve data transformation and loading into a data warehouse. Moreover, ETL pipelines always run in batches unlike a data pipeline that can be continuous, real-time, or hybrid.
ETL pipelines are mostly used for data migration, deep analytics, and business intelligence where data is extracted from varied sources and requires transformation for easy accessibility for the end users at a centralized destination. A data pipeline is more suitable for real-time applications. Both have different features and benefits and are thus chosen based on the needs of an organization.
Building Data Pipelines
Although, we can see a lot of standardization in this space, data pipelines must be carefully designed to deal with the challenges of data volume, variety, and velocity while also meeting the needs of high accuracy, low latency, and no data loss. Several decisions are required to be taken when designing data pipelines.
Should data pipeline be built in-house or on cloud?
Data pipelines are either built on-premises by an organization such as done by Spotify which uses its in-house pipeline for understanding their user preferences, mapping customers and analyzing data. However, this can be challenging as it would require developers to write new codes for every source that is to be integrated as the sources might use different technologies. Moreover, with in-house data pipelines, managing high volumes, maintaining low latency, supporting high velocity, and ensuring scalability could become challenging and cost intensive.
Other organizations use cloud-native warehouses such as Amazon Redshift, Google BigQuery, Azure SQL Data Warehouse, and Snowflake that come with easy and instant scalability benefits. Cloud based data pipelines are cost effective, fast, and provide monitoring mechanisms for handling failures and anomalies. Moreover, cloud data pipelines also enable real-time analytics that deliver business insights quickly.
Another alternative is to make use of open-source tools to build an inexpensive data pipeline. However, these open tools are available to every and can be edited in anyways. This requires a user or developer to have a high-level of technical knowledge.
What features should the pipeline require to create a competitive advantage for a business?
Modern data pipelines provide features like schema management, incremental data loading, zero data loss, fault-tolerant architecture, scalability, continuous processing, Exactly-Once processing, and live monitoring.
Schema management: Involves automatic mapping of incoming data from the sources with the schemas in the destination
Fault-tolerant architecture: A distributed architecture makes a data pipeline more reliable by mitigating impacts of failovers on critical business applications.
Infrastructure Scalability: Scalable pipelines are agile and elastic that allow upscaling and downscaling of resources anytime depending on the workloads and data storage requirements.
Continuous processing: Continuous or real-time processing enables more current data and avoids any data processing lags.
Exactly-Once processing: Advanced checkpoints keep track of events processed in a pipeline thereby ensuring that none are missed or duplicated. In case of a transfer failure, a quick rewind or replay is enabled to ensure that data is processed.
Live Monitoring: The data flow can be monitored in the real-time to check where data is any time.
How to design a data pipeline?
Data is obtained from multiple sources; goes through a series of processes like cleaning, aggregation, and transformation; and can be forwarded to multiple destinations. As a result, the data in a pipeline goes through different types of processing flows involving a series of activities. These activities and flows are represented by a directed acyclic graph (DAG) which is a conceptual model of a data pipeline.
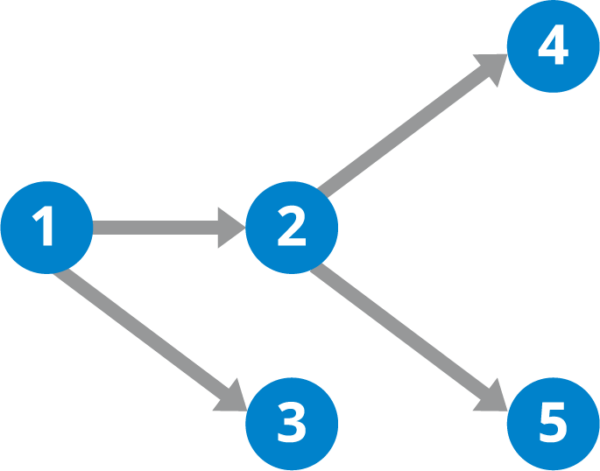
Figure 1: DAG example (Source: Hazelcast)
DAGs can be useful for representing workflows in both batch and stream data processing. Developers use DAG to monitor status of tasks involved as well as diagnose issues using logging mechanisms.
Another popular design pattern is the façade pattern which is used when APIs are involved that need to be kept separated from the DAG layer. These different patterns are not normally used exclusively but are combined to generalize data pipelines and increase abstraction.
When designing a data pipeline, creation and structuring of logging and monitoring can be separated such that DAG codes can work without any dependencies. This type of pattern is called structural. An alternative is to this is to use the responsibility principle by assigning behavior to individual objects without affecting behavior of other connected objects. This approach enhances readability and cohesion in coding.
When building automation, continuous delivery of data from source to production environment in the form of deployable packages is needed. For this, specific pipeline design patterns may be followed such as:
- Codifying pipeline logic and storing it alongside applications
- Reusable libraries containing common pipeline logic are independently developed and tested
- Pipelines are logically separated and built to run independently
- All commits, merges, and pull requests are joined to trigger the pipeline behavior
- Commits are used to trigger pipelines that are optimized for speed
- Versionable packages that can be triggered by automated events are deployed
- Releases are tagged in the production environment and documentation is automated to leave a trail
Are there any standard data pipeline design patterns?
In traditional architectures, processing and storage engine were coupled but modern architectures use decoupled processing engines. Thus, approach to designing data pipelines is largely dependent on processing of data that can be batch, stream, or combined. Lambda architecture, kappa architecture and Apache Beam are the most used architectural designs in modern data pipelines. They all combine batch and stream analytics based on properties of data and types of queries. They typically follow the three-stage pattern of data pipeline that consists of ingest stage that involves data aggregation, storage-processing where data is transformed and serving stage where data is made available to the user or decision maker through dashboards or exports. These architectures can follow two copy, one copy or zero copy patterns to manage data storage and transformation.
In a Two+ COPY Pattern, two or more stores are used for data lakes and serving layer separately. One COPY pattern uses one storage that combines processing engine and serving layer. An example could be copying source data into S3 data lake in AWS. The Zero COPY pattern doesn’t involve any movement of data but uses data virtualization solutions like Dremio to execute queries on source for creating replicas or transactional databases such as AWS Aurora to handle workloads.
Building a data pipeline with Lambda Architecture
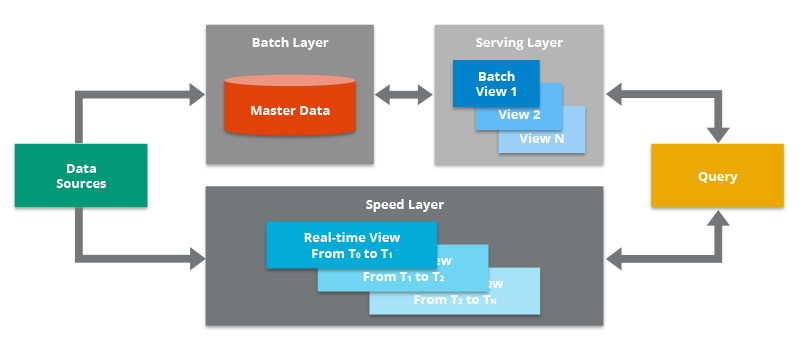
Figure 2: Lambda Architecture (Source: Hazelcast)
Lambda architecture is a deployment model for data pipelines that combined both batch and stream processing and is commonly used today to support data-driven applications. The architecture has three layers – batch, service, and speed.
The batch layer saves the input data, typically in a CSV (Comma Separated Values) format and the next serving layer indexes this data parallelly queuing up the data as the batches keep arriving. Since the batch layer is based on distributed systems, it offers high fault-tolerance for failure.
Next, the speed layer adds the latest real-time streamed data to the model. Thus, queries can be raised to both serving and speed layers to gather consolidated data. Since the historical data and latest data sits on two separate layers, they can be queried exclusively thereby saving processing time and reducing latency.
Moreover, with sequential processing, there is no overlap in data and thus, consistency is maintained in both layers. Lambda architecture enables horizontal scalability across all layers making it easy to add nodes as and when needed.
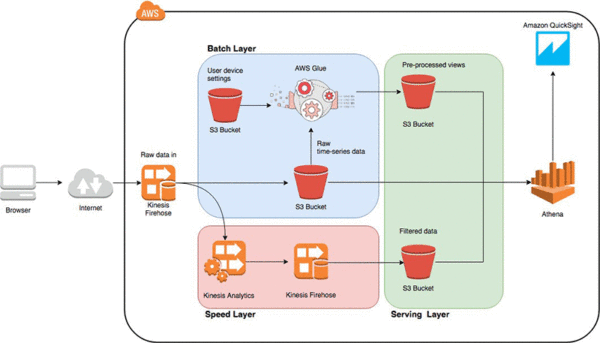
Figure 3: AWS Lambda Serverless Architecture (Source: AWS)
The figure above shows an example of AWS Lambda architecture that unified batch analytics and real-time data streams in a single code. Traditional lambda architectures required multiple systems and services for managing data ingestion, batch processing, stream processing, serving, and reporting. However, AWS Glue, which is used to build Lambda Architecture, runs without servers offering fully managed ETL services that doesn’t require users to manage clusters or servers but directly discover data and execute transformation and loading processes.
Serverless architectures can help reduce the need for back-end maintenance, enhance scalability, allow processing of huge data sets, and reduce cost with flexible pricing models. AWS Glue costs a mere $0.44 each hour for processing data and users are charged only $1 for a million requests to a data catalog. AWS Lamba users shell out mere $0.20 for a million requests
The Basics of Data Pipeline
A data pipeline is a means of moving data between a source system and a target repository. Along the way, data is transformed and optimized so that when it arrives at its final destination, it can be used to create business insights. Data pipelines are critical to enterprise operations because they eliminate most manual steps of the data processing workflow and enable real-time analytics to help business users make fast, data-driven decisions. Understand what a data pipeline is, how it differs from ETLs, as well as data pipeline design patterns and architectures can give you a holistic view of the data transfer process so you can better understand what is happening to your valuable information.
Apexon offers 360-degree analytics capabilities for managing and leveraging data across the enterprise. To learn more, check out Apexon’s Data Services or get in touch directly using the form below.



